Indexação da Base de Código
A Indexação da Base de Código permite a busca semântica de código em todo o seu projeto usando embeddings de IA. Em vez de procurar por correspondências exatas de texto, ela entende o significado de suas consultas, ajudando o AI Cockpit Reasoning a encontrar código relevante mesmo quando você não sabe nomes de funções ou locais de arquivos específicos.
O Que Faz
Quando ativado, o sistema de indexação:
- Analisa seu código usando o Tree-sitter para identificar blocos semânticos (funções, classes, métodos)
- Cria embeddings de cada bloco de código usando modelos de IA
- Armazena vetores em um banco de dados Qdrant para busca rápida por similaridade
- Fornece a ferramenta
codebase_searchpara o AI Cockpit Reasoning para descoberta inteligente de código
Isso permite que consultas em linguagem natural como "lógica de autenticação de usuário" ou "manipulação de conexão com o banco de dados" encontrem código relevante em todo o seu projeto.
Principais Benefícios
- Busca Semântica: Encontre código pelo significado, não apenas por palavras-chave
- Compreensão Aprimorada da IA: O AI Cockpit Reasoning pode compreender e trabalhar melhor com sua base de código
- Descoberta Entre Projetos: Pesquise em todos os arquivos, não apenas nos que estão abertos
- Reconhecimento de Padrões: Localize implementações e padrões de código semelhantes
Requisitos de Configuração
Provedor de Embedding
Escolha uma destas opções para gerar embeddings:
OpenAI (Recomendado)
- Requer chave de API da OpenAI
- Suporta todos os modelos de embedding da OpenAI
- Padrão:
text-embedding-3-small - Processa até 100.000 tokens por lote
Gemini
- Requer chave de API do Google AI
- Suporta modelos de embedding do Gemini, incluindo
gemini-embedding-001 - Alternativa econômica ao OpenAI
- Embeddings de alta qualidade para compreensão de código
Ollama (Local)
- Requer instalação local do Ollama
- Sem custos de API ou dependência de internet
- Suporta qualquer modelo de embedding compatível com Ollama
- Requer configuração da URL base do Ollama
Banco de Dados Vetorial
Qdrant é necessário para armazenar e pesquisar embeddings:
- Local:
http://localhost:6333(recomendado para testes) - Nuvem: Qdrant Cloud ou instância auto-hospedada
- Autenticação: Chave de API opcional para implantações seguras
Configurando o Qdrant
Configuração Rápida Local
Usando Docker:
docker run -p 6333:6333 qdrant/qdrant
Usando Docker Compose:
version: '3.8'
services:
qdrant:
image: qdrant/qdrant
ports:
- '6333:6333'
volumes:
- qdrant_storage:/qdrant/storage
volumes:
qdrant_storage:
Implantação em Produção
Para uso em equipe ou produção:
- Qdrant Cloud - Serviço gerenciado
- Auto-hospedado na AWS, GCP ou Azure
- Servidor local com acesso à rede para compartilhamento em equipe
Configuração
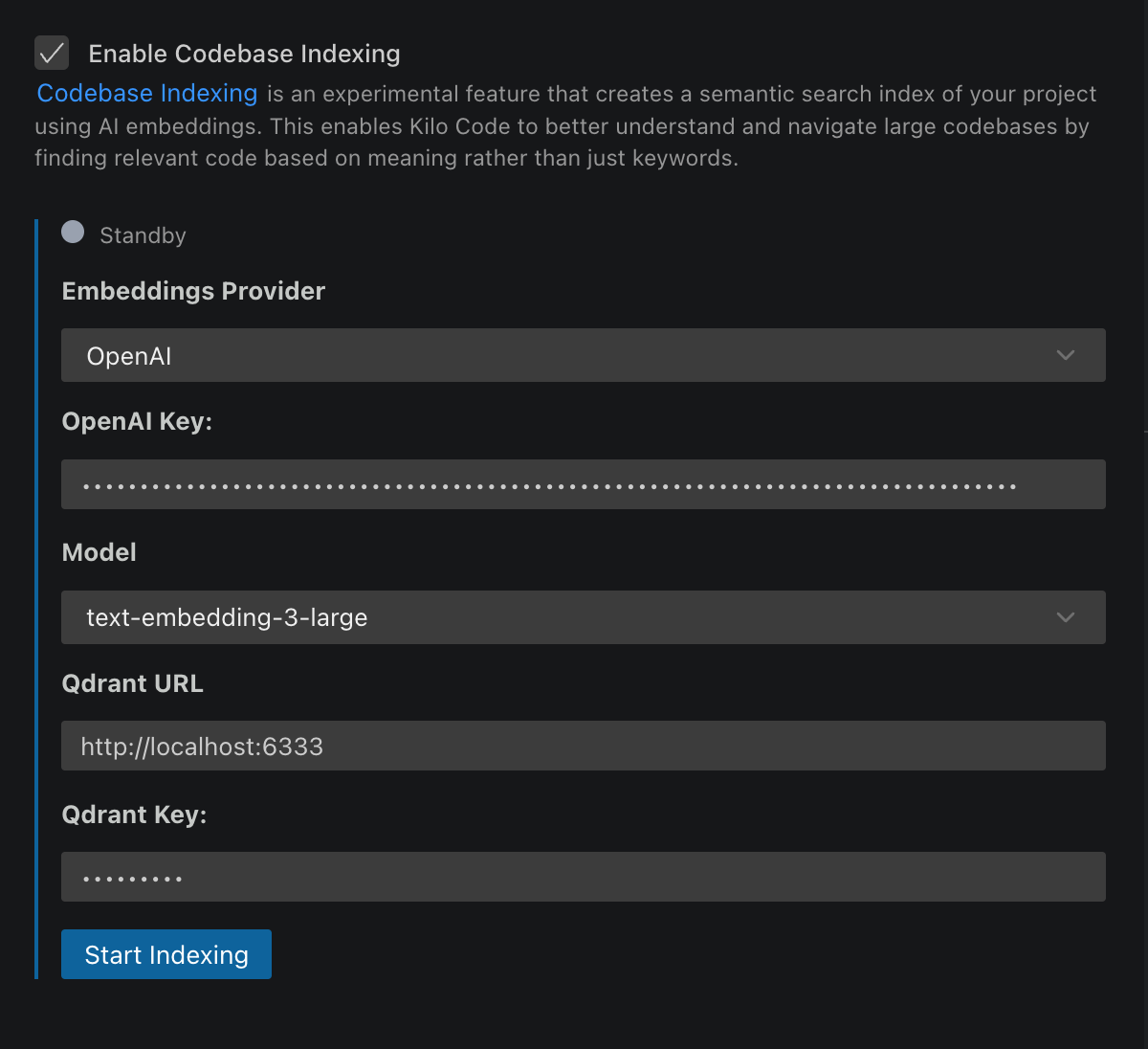
- Abra as configurações do AI Cockpit Reasoning (ícone )
- Navegue até a seção Indexação da Base de Código
- Ative "Habilitar Indexação da Base de Código" usando o interruptor
- Configure seu provedor de embedding:
- OpenAI: Insira a chave de API e selecione o modelo
- Gemini: Insira a chave de API do Google AI e selecione o modelo de embedding
- Ollama: Insira a URL base e selecione o modelo
- Defina a URL do Qdrant e a chave de API opcional
- Configure Resultados Máximos de Busca (padrão: 20, intervalo: 1-100)
- Clique em Salvar para iniciar a indexação inicial
Interruptor de Ativar/Desativar
O recurso de indexação da base de código inclui um interruptor conveniente que permite:
- Ativar: Iniciar a indexação da sua base de código e disponibilizar a ferramenta de busca
- Desativar: Parar a indexação, pausar o monitoramento de arquivos e desativar a funcionalidade de busca
- Preservar Configurações: Sua configuração permanece salva ao desativar
Este interruptor é útil para desativar temporariamente a indexação durante trabalhos de desenvolvimento intensivo ou ao trabalhar com bases de código sensíveis.
Entendendo o Status do Índice
A interface mostra o status em tempo real com indicadores coloridos:
- Em espera (Cinza): Não está em execução, aguardando configuração
- Indexando (Amarelo): Processando arquivos atualmente
- Indexado (Verde): Atualizado e pronto para buscas
- Erro (Vermelho): Estado de falha que requer atenção
Como os Arquivos São Processados
Análise Inteligente de Código
- Integração com Tree-sitter: Usa análise AST para identificar blocos de código semânticos
- Suporte a Idiomas: Todos os idiomas suportados pelo Tree-sitter
- Suporte a Markdown: Suporte completo para arquivos markdown e documentação
- Alternativa: Divisão baseada em linhas para tipos de arquivo não suportados
- Dimensionamento de Bloco:
- Mínimo: 100 caracteres
- Máximo: 1.000 caracteres
- Divide funções grandes de forma inteligente
Filtragem Automática de Arquivos
O indexador exclui automaticamente:
- Arquivos binários e imagens
- Arquivos grandes (>1MB)
- Repositórios Git (pastas
.git) - Dependências (
node_modules,vendor, etc.) - Arquivos que correspondem aos padrões
.gitignoree.AI Cockpitcode
Atualizações Incrementais
- Monitoramento de Arquivos: Monitora o espaço de trabalho em busca de alterações
- Atualizações Inteligentes: Reprocessa apenas os arquivos modificados
- Cache Baseado em Hash: Evita o reprocessamento de conteúdo inalterado
- Troca de Branch: Lida automaticamente com as mudanças de branch do Git
Melhores Práticas
Seleção de Modelo
Para OpenAI:
text-embedding-3-small: Melhor equilíbrio entre desempenho e custotext-embedding-3-large: Maior precisão, 5x mais carotext-embedding-ada-002: Modelo legado, menor custo
Para Ollama:
mxbai-embed-large: O maior e de mais alta qualidade modelo de embedding.nomic-embed-text: Melhor equilíbrio entre desempenho e qualidade de embedding.all-minilm: Modelo compacto com menor qualidade, mas desempenho mais rápido.
Considerações de Segurança
- Chaves de API: Armazenadas com segurança no armazenamento criptografado do VS Code
- Privacidade do Código: Apenas pequenos trechos de código são enviados para embedding (não arquivos completos)
- Processamento Local: Toda a análise ocorre localmente
- Segurança do Qdrant: Use autenticação para implantações em produção
Limitações Atuais
- Tamanho do Arquivo: Máximo de 1MB por arquivo
- Espaço de Trabalho Único: Um espaço de trabalho por vez
- Dependências: Requer serviços externos (provedor de embedding + Qdrant)
- Cobertura de Idiomas: Limitado aos idiomas suportados pelo Tree-sitter para uma análise otimizada
Usando o Recurso de Busca
Uma vez indexado, o AI Cockpit Reasoning pode usar a ferramenta codebase_search para encontrar código relevante:
Exemplos de Consultas:
- "Como a autenticação de usuário é tratada?"
- "Configuração da conexão com o banco de dados"
- "Padrões de tratamento de erros"
- "Definições de endpoint da API"
A ferramenta fornece ao AI Cockpit Reasoning:
- Trechos de código relevantes (até o limite máximo de resultados configurado)
- Caminhos de arquivo e números de linha
- Pontuações de similaridade
- Informações contextuais
Configuração dos Resultados da Busca
Você pode controlar o número de resultados de busca retornados ajustando a configuração Resultados Máximos de Busca:
- Padrão: 20 resultados
- Intervalo: 1-100 resultados
- Desempenho: Valores mais baixos melhoram a velocidade de resposta
- Abrangência: Valores mais altos fornecem mais contexto, mas podem tornar as respostas mais lentas
Privacidade e Segurança
- O código permanece local: Apenas pequenos trechos de código são enviados para embedding
- Embeddings são numéricos: Não são representações legíveis por humanos
- Armazenamento seguro: Chaves de API criptografadas no armazenamento do VS Code
- Opção local: Use o Ollama para processamento completamente local
- Controle de acesso: Respeita as permissões de arquivo existentes
Melhorias Futuras
Melhorias planejadas:
- Provedores de embedding adicionais
- Indexação de múltiplos espaços de trabalho
- Opções aprimoradas de filtragem e configuração
- Capacidades de compartilhamento em equipe
- Integração com a busca nativa do VS Code